メールアドレスで「同じ人」を見つける ── 名寄せ・ID統合の段階的アプローチ
複数の顧客テーブルを統合しようとした瞬間、ほぼ必ず最初に直面する問いがあります。「この行と、あの行は、同じ人なのか」。
この記事は、その問いに メールアドレスを手がかりに段階的に答えていく ための考え方を、データアナリスト・データエンジニアの視点で整理したものです。読み終わると、雑に WHERE email = email で結合する前に、自分が今どの段階の名寄せをしているのか・何を信用しすぎているのか を言語化できるようになります。
特定の業務データには触れず、設計の型だけを取り出して書いています。
「名寄せ」が解いている問題
名寄せ(identity resolution / record linkage:異なるレコードが、現実世界の同じ実体(人・法人・端末)を指しているかどうか判定する作業) は、データ統合のあらゆる場面で最初に立ちはだかる課題です。社内に散らばった顧客テーブル、CRM、決済ログ、メールマーケのリスト ── これらを横串で見るためには、まず「同じ人」を束ねる軸が必要です。
その軸として メールアドレス はとても便利です。理由は 3 つあります。
| 理由 | 内容 |
|---|---|
| 識別子としての強さ | ほとんどのサービスは email をログイン ID か通知先として保持するため、欠損が少ない |
| 文字列で完結する | 電話番号や氏名と違い、フォーマットの揺れが小さい(小さいだけで、ゼロではない) |
| 横断的に共通する | 自社サービスを跨いでも、同じ人は同じ email を使うことが多い |
しかし「便利」と「一意」は違います。email はそのままでは識別子として一意でも安定でもありません。ここを軽く見ると、最後にとんでもない数のレコードが「同じ人」として誤統合されます。
単純に email = email で突合すると、何が起きるか
実装を始める前に、素朴な完全一致だけで突合すると壊れるパターン を並べておきます。これらが頭に入っていないと、段階を分ける必要性そのものが腹落ちしません。
| 壊れ方 | 例 |
|---|---|
| 大文字小文字の違い | [email protected] と [email protected] を別人扱いする |
| 前後の空白・全角混在 | フォームから入った [email protected](先頭スペース)や全角 @ の混入 |
| Gmail のドット・エイリアス | [email protected] / [email protected] / [email protected] は全部同じ受信箱 |
| 1 人で複数 email | 仕事用 / 個人用 / キャリアメール / フリーメールを使い分ける |
| 1 つの email を複数人で共有 | info@, contact@, sales@ のような 代表メール や、家族・部署で共有しているケース |
| ドメインの別名 | googlemail.com と gmail.com、社名変更前後の旧ドメイン |
| email の使い回し | 退職・解約後にその email アドレスが別人に再割り当てされる |
ポイントは、これらの壊れ方が「等価」ではない ことです。大文字小文字の違いは正規化で潰せますが、「1 つの email を複数人で共有」は正規化では解けません。段階を分けて、各段階で扱える壊れ方だけを扱う ── これが名寄せの基本姿勢です。
段階的アプローチの全体像
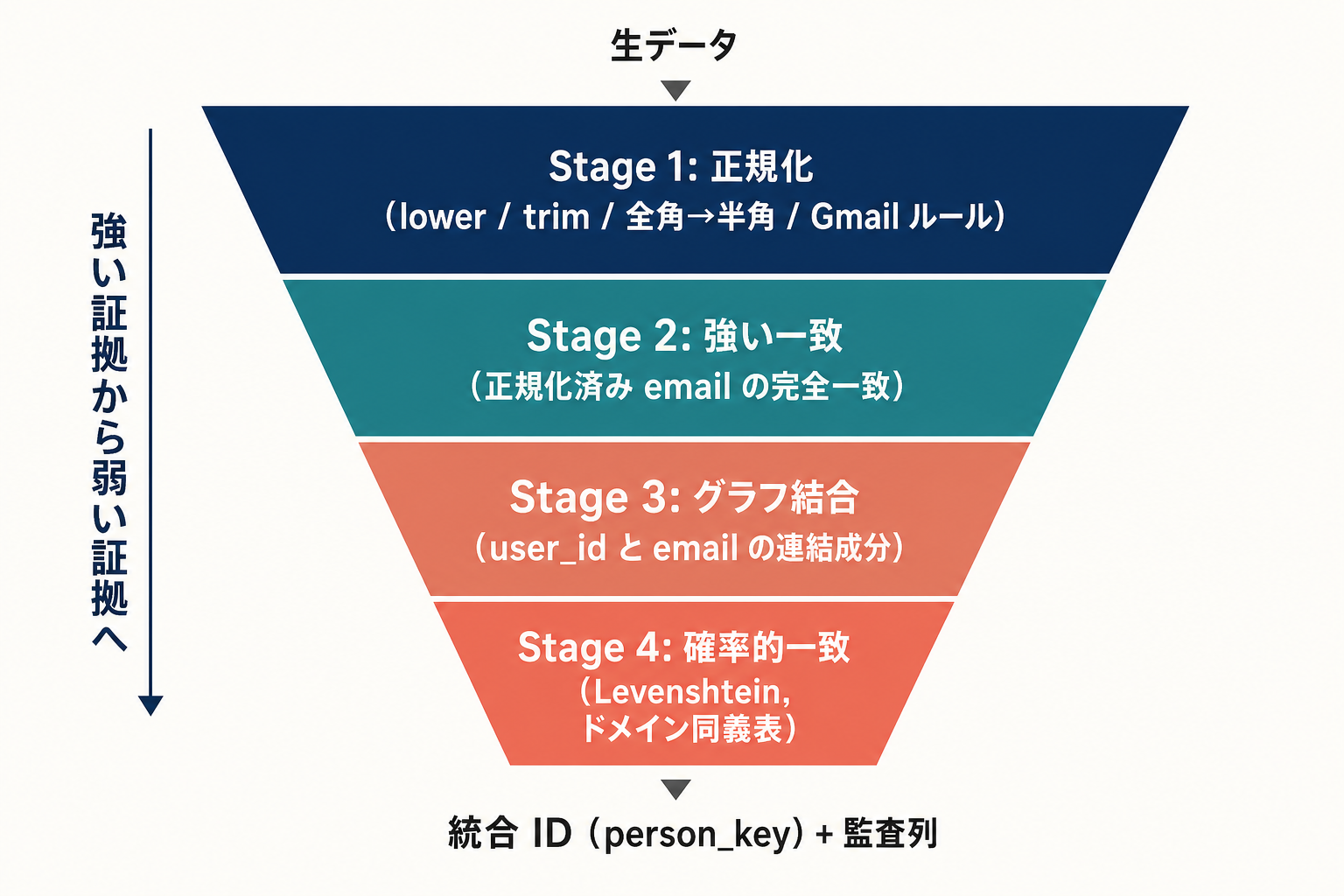
メールアドレスを軸にした名寄せは、次の 4 段階で進めるとほどよく整理できます。強い証拠から弱い証拠へ、上から下へ 降りていくイメージです。
Stage 0: 生データ(生 email、生 user_id、生 created_at)
│
▼
Stage 1: 正規化(normalize)
┌──────────────────────────────────────────┐
│ 小文字化 / trim / 全角→半角 / Gmail ルール │
└──────────────────────────────────────────┘
│
▼
Stage 2: 強い一致(deterministic match)
┌──────────────────────────────────────────┐
│ 正規化済み email が完全一致するレコードを │
│ 「同一人物の候補」として束ねる │
└──────────────────────────────────────────┘
│
▼
Stage 3: グラフで束ねる(graph-based clustering)
┌──────────────────────────────────────────┐
│ user_id ↔ email の二部グラフを作り、 │
│ 連結成分(Union-Find)を 1 人とみなす │
└──────────────────────────────────────────┘
│
▼
Stage 4: 確率的一致(probabilistic / fuzzy)
┌──────────────────────────────────────────┐
│ Levenshtein 等のあいまい一致や │
│ ドメイン同義表で「弱い証拠」を補う │
└──────────────────────────────────────────┘
│
▼
最終出力: 統合 ID(person_key)と監査列各段階で「何を信用するか・しないか」を宣言する。これがあると、あとから「なぜこの 2 行を同じ人にしたのか」を説明できます。逆にここが曖昧だと、半年後に 誤統合の責任を誰も取れない統合済みテーブル が残ります。
Stage 1: 正規化(normalize)
最初の段階は、人間にとって同じ意味の email 文字列を、ビット列としても同じにする 作業です。やることは地味ですが、ここで漏れた揺れは後段すべてに引きずります。
共通正規化ルール
| 項目 | ルール | 理由 |
|---|---|---|
| 小文字化 | ローカル部・ドメイン部とも lower() | RFC 5321(メール送受信の仕様)でドメイン部は大文字小文字無視。ローカル部は厳密には大小区別ありだが、現実のメールサーバはほぼ区別しない |
| 前後空白除去 | trim() | フォーム入力で末尾改行・先頭スペースが混入する |
| 全角→半角 | @ と英数字を半角化 | 日本語フォームで全角混入が起きる |
| 不可視文字除去 | ゼロ幅スペース等 | コピペ経由で混入する |
| ドメイン同義の正規化 | googlemail.com → gmail.com 等 | サービス側で同等扱いされている既知の別名のみ |
Gmail / Google Workspace 特有のルール
Gmail には独自仕様が 2 つあります。これを知らないと、同じ受信箱に届く別文字列の email を別人と数えてしまいます。
- ドット無視:
[email protected]と[email protected]は同じアカウント +以降無視:[email protected]の+news部分はサーバ側で削ぎ落とされる(ユーザーが受信メールを振り分けるためのタグ)
注意点があります。これは Gmail / Google Workspace のホスト固有の仕様 であり、他社の email サーバでは [email protected] と [email protected] は別人かもしれません。ドメインを判定してから個別ルールを適用する のが安全です。
SQL での正規化例
BigQuery 風に書くとこうなります。
WITH normalized AS (
SELECT
user_id,
raw_email,
LOWER(TRIM(raw_email)) AS lowered,
LOWER(SPLIT(TRIM(raw_email), '@')[SAFE_OFFSET(0)]) AS local_part_raw,
LOWER(SPLIT(TRIM(raw_email), '@')[SAFE_OFFSET(1)]) AS domain_part
FROM raw_users
WHERE raw_email IS NOT NULL
),
applied AS (
SELECT
user_id,
raw_email,
lowered,
-- ドメイン正規化(Gmail 同義の名寄せ)
CASE
WHEN domain_part IN ('gmail.com', 'googlemail.com') THEN 'gmail.com'
ELSE domain_part
END AS domain_norm,
-- ローカル部正規化(Gmail のときだけ . と +alias を削る)
CASE
WHEN domain_part IN ('gmail.com', 'googlemail.com') THEN
REGEXP_REPLACE(SPLIT(local_part_raw, '+')[SAFE_OFFSET(0)], r'\.', '')
ELSE local_part_raw
END AS local_norm
FROM normalized
WHERE local_part_raw IS NOT NULL
AND domain_part IS NOT NULL
)
SELECT
user_id,
raw_email,
CONCAT(local_norm, '@', domain_norm) AS email_key,
-- どのルールを適用したか後段の監査用に残す
CASE
WHEN domain_norm = 'gmail.com' THEN 'gmail_dot_plus_stripped'
ELSE 'lower_trim_only'
END AS normalize_rule
FROM applied;email_key が 後段の段階で使う「正規化済みキー」 です。raw_email は捨てずに残し続けます ── トラブル時の監査で原文に戻れるようにするためです。
正規化の境界線
ここで重要なのは「やりすぎないこと」です。例えば、独自ドメイン(自社の @example.co.jp)に対して Gmail のドットルールを適用すると、本来別人の [email protected] と [email protected] を同一人物にしてしまいます。汎用ルール(lower / trim)と、ホスト固有ルール(Gmail)は明確に分けて、後者はホワイトリストドメインにしか適用しない ── これが鉄則です。
Stage 2: 強い一致(deterministic match)
正規化済みの email_key で完全一致する行を、「同じ人物の候補」として束ねる 段階です。ここで便宜的な統合 ID、person_key を払い出します。
シンプルな束ね方
WITH email_groups AS (
SELECT
email_key,
ARRAY_AGG(DISTINCT user_id ORDER BY user_id) AS user_ids,
COUNT(DISTINCT user_id) AS user_id_count
FROM normalized_users
GROUP BY email_key
)
SELECT
email_key,
user_ids,
user_id_count,
-- email_key そのものを person_key の暫定値にする
TO_HEX(SHA256(email_key)) AS person_key
FROM email_groups;この時点で、user_id_count >= 2 の行は 「複数の user_id が同じ email を共有している」 ということを意味します。これが Stage 3 への橋渡しになります。
「強い」とはどういう意味か
ここで束ねた候補は、正規化済み email が完全一致したという事実だけ に基づいています。これは強い証拠ですが、絶対ではありません。
- 代表メール(
info@,contact@,sales@)は 複数の人物が共有する ため、ここで束ねると人格が混ざる - email の使い回し(退職後の再割り当て)は、過去のレコードと現在のレコードを別人にすべき
実務では、この段階で 黒リストドメイン(フリーメールの代表系)と共有 email パターンを除外 したうえで束ねるのが安全です。
-- 共有 email を除外する例
SELECT *
FROM email_groups
WHERE NOT REGEXP_CONTAINS(email_key, r'^(info|contact|support|sales|admin|noreply|no-reply)@')
AND user_id_count <= 5 -- 1 つの email に紐づく user_id 数の上限を仮置き<= 5 の閾値は 観察値から決める べきです。自社データでヒストグラムを取り、自然な裾(家族共有や法人代表で説明できる範囲)を超えるロングテールを切ります。
Stage 3: グラフで束ねる(graph-based clustering)
Stage 2 までは「ある 1 つの email 軸」で束ねていました。しかしユーザーは複数の email を持ちます。
user_id=1: [email protected], [email protected]
user_id=2: [email protected], [email protected]
user_id=3: [email protected], [email protected]Stage 2 のロジックでは、[email protected] で user_id=1, 2 が束ねられ、[email protected] で user_id=2, 3 が束ねられます。しかし 「user_id=1 と user_id=3 を同じ人として扱うか」 は明示的に判定していません。
ここで効くのが グラフ的アプローチ です。
二部グラフと連結成分
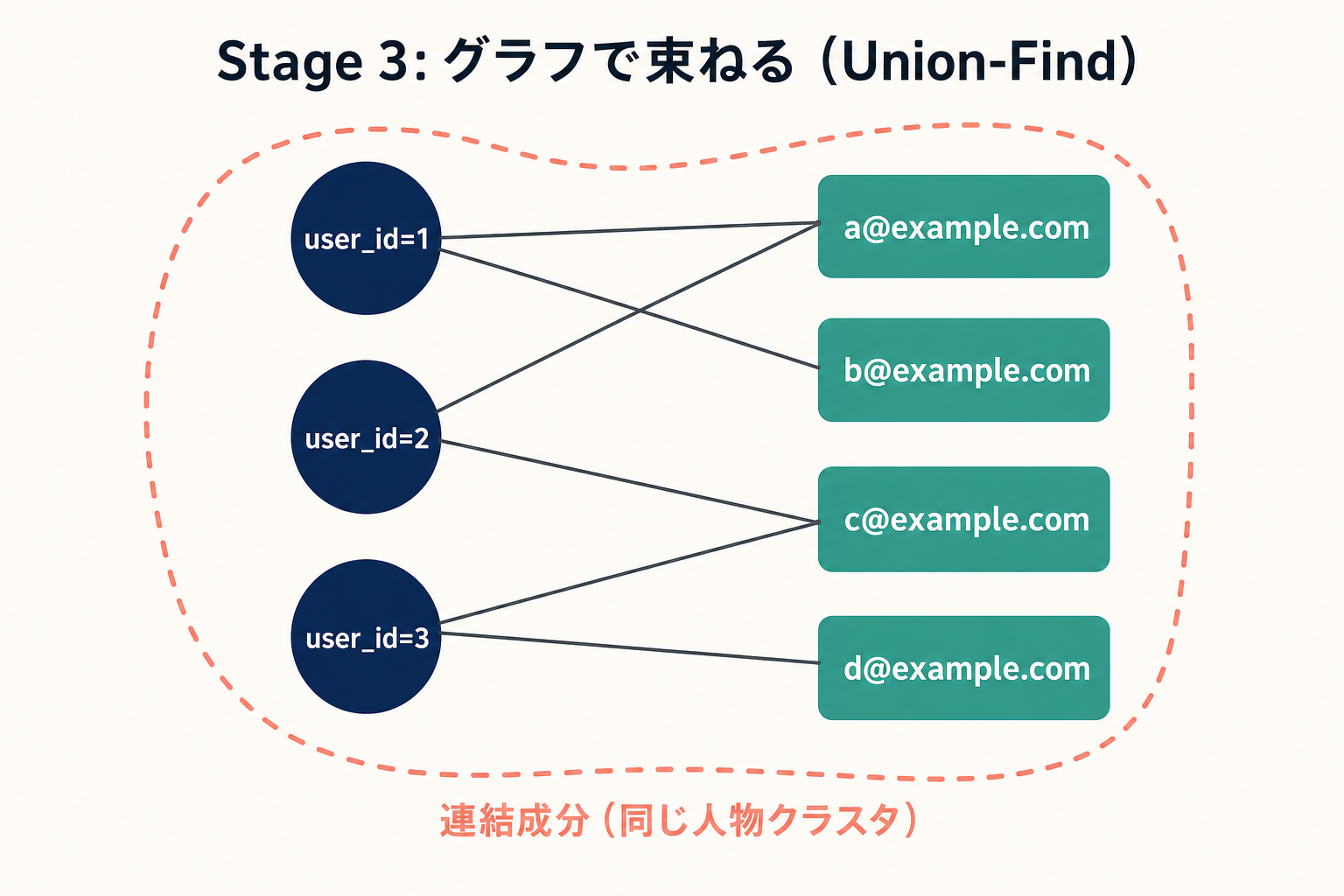
user_id と email_key を ノード、両者の紐付きを エッジ とする 二部グラフ(bipartite graph:ノードが 2 種類に分かれ、エッジが 2 種類間でしか張られないグラフ) を作ります。
user_id=1 ─── [email protected]
│
└─────── [email protected]
user_id=2 ─── [email protected]
│
└─────── [email protected]
user_id=3 ─── [email protected]
│
└─────── [email protected]このグラフの 連結成分(connected component:エッジを辿って到達できるノードの最大集合) を 「同じ人物」のクラスタ とみなします。
連結成分:
{ user_id=1, user_id=2, user_id=3,
[email protected], [email protected], [email protected], [email protected] }これを 1 つの person_key に束ねます。
Union-Find(素集合データ構造)
連結成分を求める定番アルゴリズムが Union-Find(素集合データ構造、Disjoint Set Union とも:要素の所属クラスタを高速に更新・問い合わせできる構造) です。O(N · α(N)) ≒ ほぼ線形で処理できます。
Python での実装例:
class UnionFind:
def __init__(self):
self.parent: dict[str, str] = {}
def find(self, x: str) -> str:
if x not in self.parent:
self.parent[x] = x
return x
# 経路圧縮
root = x
while self.parent[root] != root:
root = self.parent[root]
while self.parent[x] != root:
self.parent[x], x = root, self.parent[x]
return root
def union(self, x: str, y: str) -> None:
rx, ry = self.find(x), self.find(y)
if rx != ry:
self.parent[rx] = ry
def cluster(edges: list[tuple[str, str]]) -> dict[str, str]:
"""
edges: [(node_user, node_email), ...]
例: [("user:1", "email:[email protected]"),
("user:1", "email:[email protected]"), ...]
戻り値: ノード → 代表ノード(クラスタ ID)
"""
uf = UnionFind()
for a, b in edges:
uf.union(a, b)
return {node: uf.find(node) for node in uf.parent}このとき、user と email のノードを区別する prefix(user:, email:)を必ず付ける こと。文字列が偶然一致して別世界のノード同士が束ねられる事故を防げます。
SQL だけで完結させたい場合
データウェアハウス(BigQuery / Snowflake 等)で完結させたいなら、反復クエリで段階的に親 ID を引き上げる方式 で書けます。ただし行数が増えると O(N²) に近い計算量になりがちなので、規模が小さいうちは SQL・大規模なら Python に降ろす という判断軸を持っておくとよいです。
| 規模 | 推奨 |
|---|---|
| 〜数十万エッジ | SQL での反復 JOIN |
| 数十万〜数千万エッジ | Python の Union-Find(インメモリ) |
| 数千万〜 | Spark の connectedComponents(GraphFrames) |
この段階で何が解けたか
| 解けたこと | 例 |
|---|---|
| 1 人で複数 email を持つ | a@, b@ を共有する user_id=1 を束ねる |
| email 経由の間接的な紐付け | user_id=1 ↔ a@ ↔ user_id=2 ↔ c@ ↔ user_id=3 を 1 クラスタにする |
| まだ解けていないこと | 例 |
|---|---|
| email の表記ゆれ(タイポ) | [email protected] / [email protected](gnail は gmail のタイポ) |
| ドメイン名の同義 | 既知でない別名(社名変更前後の旧ドメイン) |
これは Stage 4 の領域です。
Stage 4: 確率的一致(probabilistic / fuzzy match)
確率的一致は、「決定的には同じと言えないが、状況証拠として高い確率で同じ」 な行を束ねる段階です。代表的な道具は次の通り。
| 道具 | 用途 |
|---|---|
| Levenshtein 距離(ある文字列を別の文字列に変える最小編集回数) | gnail.com ↔ gmail.com のような 1 文字違い を検出 |
| Jaro-Winkler 距離(前方一致を重く評価する文字列類似度) | 氏名の表記ゆれにも使える |
| ドメイン同義表 | 既知の別名・買収後の統合ドメインを手で持つ |
| 補助フィーチャー | 氏名・住所・電話番号など email 以外 の状況証拠で確からしさを上げる |
よくある実装
import Levenshtein
def is_likely_typo(domain_a: str, domain_b: str) -> bool:
"""ドメイン部のタイポ判定(保守的)"""
if domain_a == domain_b:
return False
distance = Levenshtein.distance(domain_a, domain_b)
if distance != 1:
return False
# 元が 6 文字以上のときだけ採用(短いドメインは別物の確率が上がる)
return min(len(domain_a), len(domain_b)) >= 6ポイントは 「閾値を保守的に」 取ることです。確率的一致は 誤統合(false merge)の主因 であり、ここを攻めすぎると後続の業務ロジック(マーケ配信・与信・サポート対応)すべてが汚染されます。
確率的一致を採用するときの判断軸
| 採用してよい場面 | 採用すべきでない場面 |
|---|---|
| 補助フィーチャー(氏名・住所など)が複数 hit する | email だけが状況証拠 |
| 業務影響が小さい用途(重複削減・ダッシュボード集計) | 業務影響が大きい用途(与信・課金・本人確認) |
| 監査列で「これは確率的一致由来」と明示できる | 監査列がなく、後で調べられない |
「迷ったら入れない」 が基本姿勢です。確率的一致は 後から削れる が、誤って統合した行を後から戻すのは非常に難しい ── これは経験則です。
監査列を必ず残す

ここまでの 4 段階を踏んでも、最終テーブルが 「ただの統合済み顧客テーブル」 だけだと、半年後に何も検証できません。
最終 mart には 監査列(provenance columns:そのレコードがどう作られたかの来歴を残す列) を必ず添えます。
| 列 | 内容 |
|---|---|
person_key | 統合 ID |
source_user_ids | 統合元の user_id 群(配列) |
source_emails | 統合元の email 群(配列、生原文) |
match_stage | この行が束ねられた最も弱い証拠の段階(stage1/stage2/stage3/stage4) |
match_rule | 適用ルール識別子(例: gmail_dot_plus_stripped, domain_alias_googlemail, levenshtein_1) |
merged_at | 統合バッチの実行時刻 |
merge_run_id | バッチ実行 ID(リプレイ可能性の担保) |
この監査列があれば、誤統合が発覚したときに その人物だけ unmerge できます。逆にこれがないと、データを巻き戻すには 過去のバッチを全部走らせ直す しかありません。
実装の選び方
最後に、どこまで SQL でやって、どこから Python に降ろすか の判断軸を整理します。
| 段階 | 推奨実装 | 理由 |
|---|---|---|
| Stage 1 (正規化) | SQL(dbt model) | 文字列処理・分岐は SQL の得意領域。再現性が高い |
| Stage 2 (強い一致) | SQL(dbt model) | GROUP BY と ARRAY_AGG で完結 |
| Stage 3 (グラフ束ね) | 規模次第(数十万まで SQL、それ以上 Python / Spark) | O(N · α(N)) を SQL で表現するのは非効率 |
| Stage 4 (確率的一致) | Python / 専用ツール(dedupe, splink 等) | 距離関数・しきい値学習・active learning が必要 |
「全部 SQL でやろうとしない」 が運用上の最適解です。Stage 3 以降を Python に降ろす境目は、データ規模より 「変更速度」 で決めると安定します。Stage 4 のしきい値はチューニングを重ねる前提なので、dbt の static SQL に閉じ込めるとイテレーションが回らなくなる からです。
よくある失敗とリカバリ
過去の名寄せ実務で踏みがちな罠を整理しておきます。
失敗 1: 代表メールを「同じ人」にしてしまう
info@, support@, contact@ を Stage 2 で素朴に束ねると、会社中の人が 1 人の超大型クラスタに合流 します。Stage 2 で除外リストを持つか、Stage 3 で「1 つの email に紐づく user_id 数」に上限を入れて検出します。
失敗 2: 退職・解約による email 再割り当てを無視する
email は 同じアドレスでも、時系列で違う人を指していることがある。完璧な解は無いものの、created_at と最終アクティビティ日時の間に長すぎる空白がある クラスタを検出して、人手で確認するフローを用意します。
失敗 3: 確率的一致を Stage 1 や Stage 2 に混ぜ込む
「ついでに gnail.com も gmail.com にしておこう」と Stage 1 に混ぜると、正規化フェーズが確率混入で汚染 されます。確率的一致は 必ず最後の段階 に置き、監査列で由来を区別すること。
失敗 4: 一度走らせて終わり、にしてしまう
新規ユーザーが入ってくれば、また Stage 1 〜 4 を回す必要があります。バッチ再実行が冪等であること(同じ入力で同じ person_key が出る)を必ず確認します。シードを使った安定ハッシュで person_key を生成すると、再実行で ID が動きません。
失敗 5: 統合先のキーを「最若番の user_id」にしてしまう
直感的に「一番古い user_id を代表にしよう」となりがちですが、新規ユーザーが入って若番が変わると person_key も動く ことになります。person_key は 入力 user_id から決定的に生成されるハッシュ にすると安全です。
まとめ
メールアドレスを軸にした名寄せは、「ステージを分けて、各ステージで何を信用するか宣言する」 作業です。
- Stage 1 (正規化): 「人間にとって同じ意味の email を、ビット列としても同じにする」
- Stage 2 (強い一致): 「正規化済み email の完全一致だけを根拠に束ねる」
- Stage 3 (グラフ結合): 「複数 email を持つ人を、グラフの連結成分で束ねる」
- Stage 4 (確率的一致): 「決定的でない証拠を、最後にだけ・監査つきで採用する」
そして全段階を通じて、監査列を必ず残し、person_key を決定的に生成する。
これだけ守れば、半年後に「なぜこの 2 人を同じ人にしたのか」と聞かれても、ステージ・ルール・元レコード で答えられる名寄せパイプラインになります。
分からない用語や「ここをもっと詳しく」があれば遠慮なく聞いてください。